There is no universally-agreed-upon way to convert the overall score of a student to the final letter grade. Many institutions (including METU) leave this to the instructor’s full discretion, and many instructors choose to do this assignment in an heuristic course-by-course manner. I instead do this assignment in an algorithmic way, which is detailed in this website for full transparency.
Let us assume that a student takes a class : at the end of the semester, the grade of the student is expected to depend both on the student and the class . Ideally, we would know the function such that , which completely takes into account both the student and the class.
Determining such a function would require us to have access to infinite information: the student may have infinitely many attributes that we should take into account (how much they study, how intelligent they are, if they lost a family member this semester, etc.), and the class may depend on infinitely many conditions (how good the instructor is, how hard the tests are, whether it is a morning class, etc.). It is impossible to find the “correct” , even if it exists.
(a) The first practical approach that we can choose is to assume the following:
Under these assumptions, the letter grade can be assigned to a student solely based on their scores, independent of the semester of the course. Therefore, we simply create score brackets (such as 90-100, 85-90, etc.), and assign letter grades based on which bracket a student’s score falls into. This is colloquially called catalog grading.
(b) The second practical approach assumes the following:
In this approach, we argue that each student has some probability to obtain some score at the end of the semester; for instance, student 1 might have probability to obtain a score greater than out of . Therefore, we can assign a probability distribution to each student, telling us their likelihood to get some particular score (such as 72 or 49). Now, if we assume that (1) these probability distributions are sufficiently similar and (2) there are sufficiently many students in the class, the probability distribution for a hypothetical average student becomes a Gaussian distribution. This follows from the Central Limit Theorem.
The letter grades of individual students are now assigned based on how well they did compared to this hypothetical average student. For instance, if a student has the score , and the probability for the hypothetical average student to get a score between and is , then the student is to be awarded the letter grade AA even though their score would be FF under the “catalog grading”. This “comparing with the gaussian” type of grading is colloquially called curve grading.
(c) There are several other approaches, which relax some of the assumptions in the other methods. For instance, one can extend the dependence on beyond the mere score of the student. This would entail including the observations of the student (such as class attendance) into the final letter grade. Despite having the potential to be somehow fairer, these methods are either non-algorithmic or non-practical for large classes, hence I do not prefer them.
There are some problems both with the catalog and traditional curve grading:
The first two problems can be solved if we cluster students into various groups: indeed, we expect students to obtain similar results if they turn in similar homeworks or make similar mistakes in the exams, so it is natural to observe clustering of students around some score points. If we identify such clusters and group them into 9 categories, we can assign letter grades in an unambiguous fair way!
There is a fast and reliable way to do just this: following Mathematica command splits the “scores” list into 9 categories, based on the clustering of the individual scores!
This, however, does not solve the third problem above as the clustering method does not distinguish different parts of the score spectrum. We can remedy this by stretching the high end of the scores and squeezing the low end –this can be achieved by the following code:
where (with default value ) is a tunable parameter ensuring the asymmetry, with restoring back the symmetry.
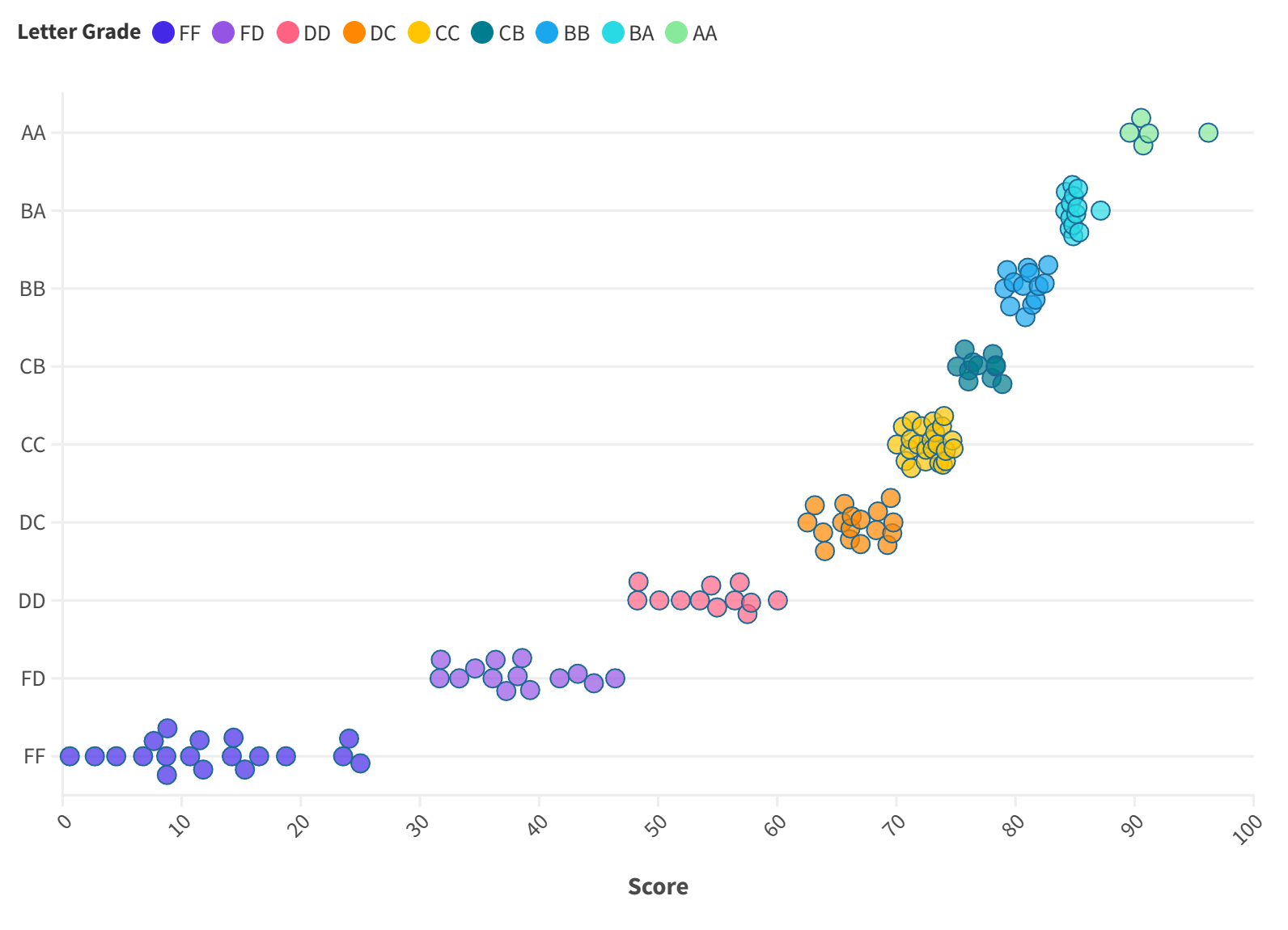
This ensures an algorithmic unambiguous grading scheme which tries to assign same letter grade to students with similar scores, and which distinguishes the effort to get more points between low and high end of the score spectrum. An actual example of how this approach led to letter grades can be seen in the following figure, which reflects the grades of my Phys209 class in 2023 Fall Semester.
One problem with this approach is the effect of outlier students who receive rather high grades: the algorithm (by design) isolate them as the sole receipents of the letter grade AA, rendering other successful (but not outlier) students receiving lower letter grades. For instance, the algorithm yields the following distribution for my Phys209 class in 2024 Fall semester:
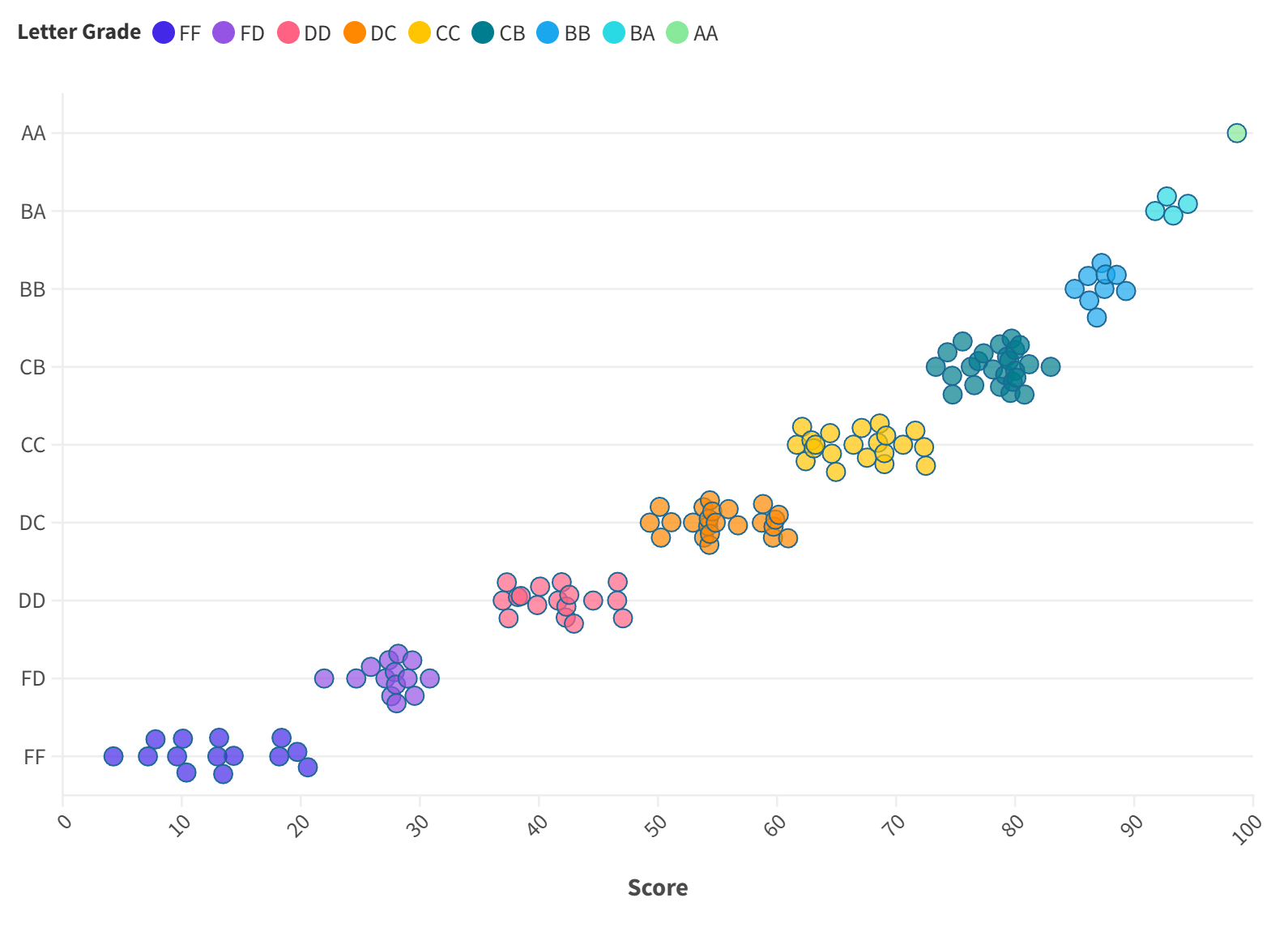
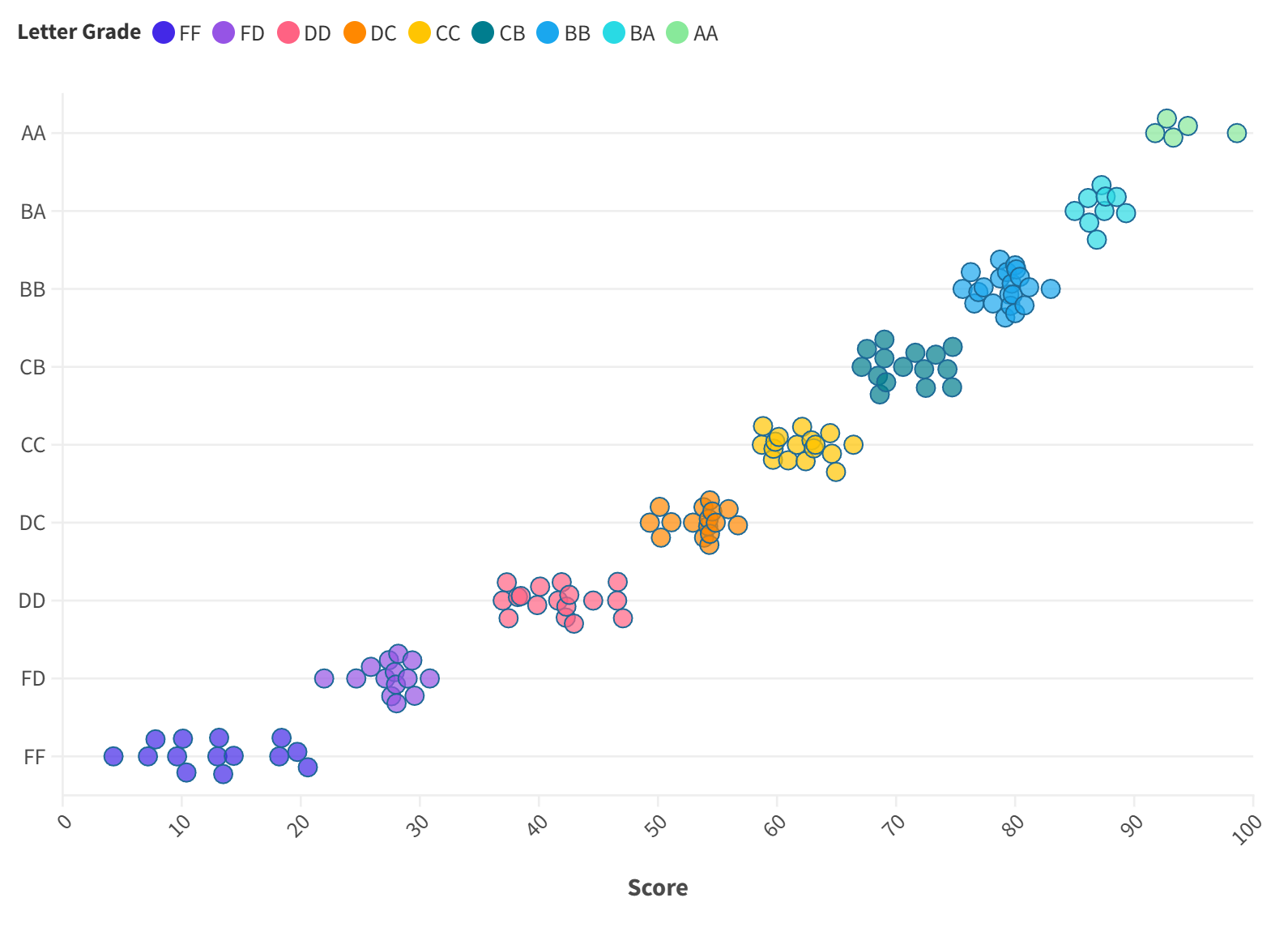
We can tweak the the parameter mentioned above to present this; we can also create more clusters and reward a few of the top clusters the grade AA. For example, for my Phys209 class in 2024 Fall semester, I created 10 clusters and awarded the top two groups the letter grade AA, leading the final distribution below.
Another solution is to explicitly specify a method for FindClusters command; for instance, for my Phys210 class in 2024 Spring semester, I chose KMeans method to ensure sufficiently many students get higher grades as can be seen in the comparison below.
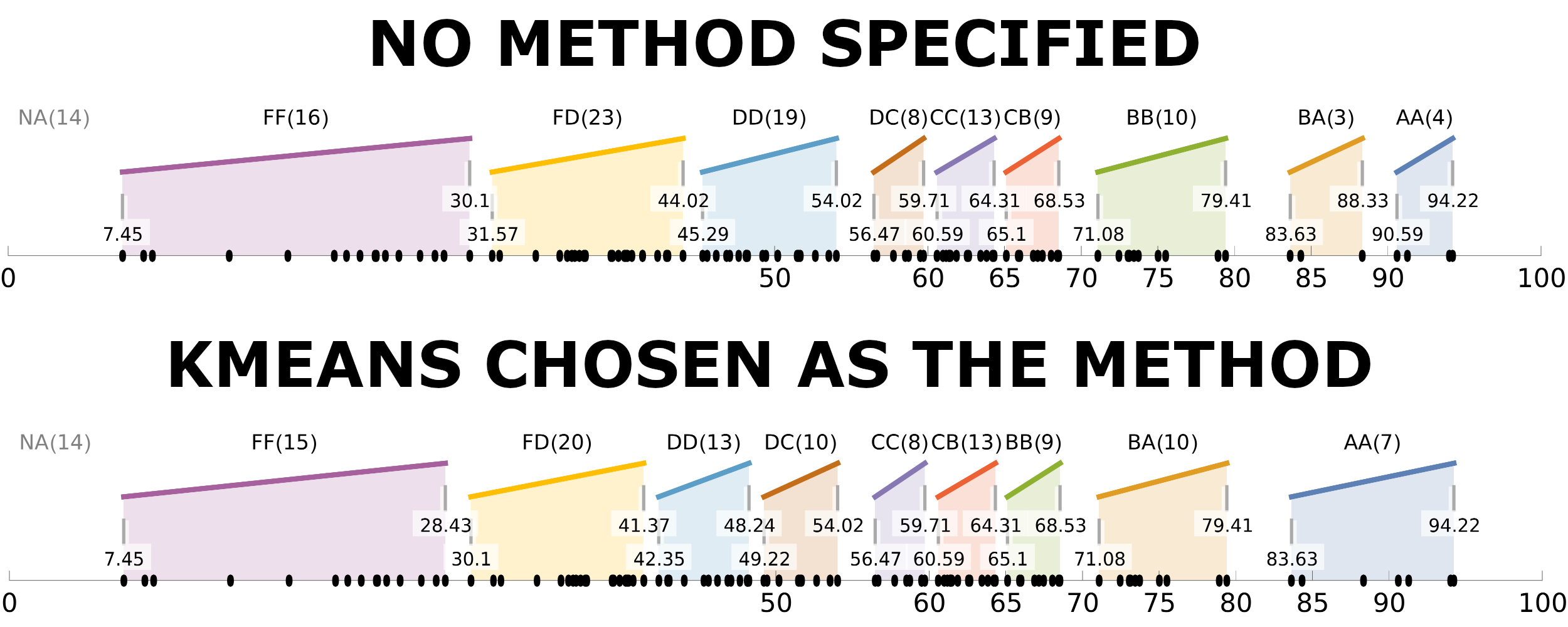
where I also took in this particular case.